Welcome to My Website
This is the place where I share my ideas.You can also visit me on @CSDN or @oschina.
Give Chapter and Verse and Author for Transshipment, copy or other using. Thanks!
-
Scala和Java二种方式实战Spark Streaming开发
一、Java方式开发
1、开发前准备
假定您以搭建好了Spark集群。
2、开发环境采用eclipse maven工程,需要添加Spark Streaming依赖。
3、Spark streaming 基于Spark Core进行计算,需要注意事项:
设置本地master,如果指定local的话,必须配置至少二条线程,也可通过sparkconf来设置,因为Spark Streaming应用程序在运行的时候,至少有一条线程用于不断的循环接收数据,并且至少有一条线程用于处理接收的数据(否则的话无法有线程用于处理数据),随着时间的推移,内存和磁盘都会不堪重负)。
温馨提示:对于集群而言,每隔exccutor一般肯定不只一个Thread,那对于处理Spark Streaming应用程序而言,每个executor一般分配多少core比较合适?根据我们过去的经验,5个左右的core是最佳的(段子:分配为奇数个core的表现最佳,例如:分配3个、5个、7个core等) 接下来,让我们开始动手写写Java代码吧!
第一步:
第二步:
我们采用基于配置文件的方式创建SparkStreamingContext对象
第三步,创建Spark Streaming输入数据来源:
我们将数据来源配置为本地端口9999(注意端口要求没有被占用):
第四步:我们就像对RDD编程一样,基于DStream进行编程,原因是DStream是RDD产生的模板,在Spark Streaming发生计算前,其实质是把每个Batch的DStream的操作翻译成为了RDD操作。
##1、flatMap操作:
2、 mapToPair操作:
3、reduceByKey操作:
4、print等操作:
温馨提示:除了print()方法将处理后的数据输出之外,还有其他的方法也非常重要,在开发中需要重点掌握,比如SaveAsTextFile,SaveAsHadoopFile等,最为重要的是foreachRDD方法,这个方法可以将数据写入Redis,DB,DashBoard等,甚至可以随意的定义数据放在哪里,功能非常强大。
二、Scala方式开发
第一步,接收数据源:
第二步,flatMap操作:
第三步,map操作:
第四步,reduce操作:
第五步,print()等操作:
第六步:awaitTermination操作
-
基于HDFS的SparkStreaming案例实战和内幕解析
概要
本节主要讲解在开发环境中编写SparkStreaming代码监控hdfs目录,实现实时wordCount计算。 先通过Java方式演示过程,并在文末提供Scala版本代码。一、环境准备
1.启动Hadoop集群
cd /usr/local/hadoop/hadoop-2.6.0/sbin/ ./start-dfs.sh //通过http://master:50070(50070为默认端口)查看datanode 的信息 ./start-yarn.sh //启动Hadoop的资源管理框架Yarn2.启动Spark集群
cd /usr/local/spark/spark-1.6.0-bin-hadoop2.6/sbin/ ./start-all.sh //打开浏览器访问http://master:8080查看spark控制台 ./start-history-server.sh //运维,启动日志来记录spark集群运行的每一步信息二、代码实战
1.定义成员变量
final String checkpointDirectory = "hdfs://Master:9000/library/SparkStreaming/CheckPoint_Data";//checkpoint存放数据的文件夹 final String dataDirectory = "hdfs://Master:9000/library/SparkStreaming/Data";//SparkStreaming监控的文件夹2.配置SparkConf
final SparkConf conf = new SparkConf().setMaster("spark://Master:7077"). setAppName("SparkStreamingOnHDFS");//设置Master端口和App名称。3、创建SparkStreamingContext
3.1 定义一个创建StreamingContext的方法
private static JavaStreamingContext createContext( String checkpointDirectory,SparkConf conf) { System.out.println("Creating new context"); SparkConf sparkConf = conf; // Create the context with a 15 second batch size JavaStreamingContext ssc = new JavaStreamingContext(sparkConf, Durations.seconds(15)); ssc.checkpoint(checkpointDirectory); return ssc; }3.2 定义工厂类创建Context
JavaStreamingContextFactory factory = new JavaStreamingContextFactory() { @Override public JavaStreamingContext create() { return createContext(checkpointDirectory, conf); } };3.3 使用StreamingContext的getOrCreate创建Context
//传入参数为checkpoint目录和工厂 JavaStreamingContext jsc = JavaStreamingContext.getOrCreate(checkpointDirectory, factory);4 编写业务代码
4.1 创建Spark Streaming输入数据来源input Stream:
JavaDStream lines = jsc.textFileStream(dataDirectory);4.2 接下来就像对于RDD编程一样基于DStream进行编程
//4.2.1 读取数据并对每一行中的数据以空格作为split参数切分成单词以获得DStream<String> JavaDStream<String> words = lines.flatMap(new FlatMapFunction<String, String>() { @Override public Iterable<String> call(String line) throws Exception { return Arrays.asList(line.split(" ")); } }); //4.2.2 使用mapToPair创建PairDStream JavaPairDStream<String, Integer> pairs = words.mapToPair(new PairFunction<String, String, Integer>() { @Override public Tuple2<String, Integer> call(String word) throws Exception { return new Tuple2<String, Integer>(word, 1); } }); //4.2.3 使用reduceByKey进行累计操作 JavaPairDStream<String, Integer> wordsCount = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() { //对相同的Key,进行Value的累计(包括Local和Reducer级别同时Reduce) @Override public Integer call(Integer v1, Integer v2) throws Exception { return v1 + v2; } }); wordsCount.print(); /* * Spark Streaming执行引擎也就是Driver开始运行,Driver启动的时候是位于一条新的线程中的,当然其内部有消息循环体,用于 * 接受应用程序本身或者Executor中的消息; */ jsc.start(); jsc.awaitTermination(); jsc.close();三、打包发布
由于项目是maven构建的,右键Spark程序的类,选择Run as选择Run Configurations。Goals设置为clean package。点击Run。构建成功后,可以在target文件夹找到名为SparkApps-0.0.1-SNAPSHOT-jar-with-dependencies.jar的文件。将此jar放置在Master机器的一个文件夹下,例如/root/Documents/SparkApps。 可能会出现的两个问题:
1.maven-compiler-plugin 插件版本信息错误。解决办法,增加一行版本信息。
<plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>2.3.2</version> //增加的版本信息。 <configuration> <source>1.6</source> <target>1.6</target> <encoding>UTF-8</encoding> </configuration> </plugin> </plugins>2.Maven Unable to locate the Javac Compiler解决办法:编辑jdk,把jre home的值修改成jdk home。
四、案例演示
4.1 在Hadoop上建立数据目录
注:创建多级目录要在-mkdir后加上-phadoop dfs -mkdir -p /library/SparkStreaming/Data hadoop dfs –mkdir /library/SparkStreaming/CheckPoint_Data4.2 提交程序
//4.2.1 进入spark的bin目录 cd /usr/local/spark/spark-1.6.0-bin-hadoop2.6/bin/ //4.2.2 spark-submit spark-submit --class com.dt.spark.MySparkApps.Streaming.SparkStreamingOnHDFS --master spark://Master:7077 /root/Documents/SparkApps/SparkApps-0.0.1-SNAPSHOT-jar-with-dependencies.jar4.3 往HDFS里传文件
hadoop dfs -put ./14.txt /library/SparkStreaming/Data4.4 运行结果:
上传了第一个文件  运行结果继续上传文件到HDFS运行结果:五、源码解析
5.1 JavaStreamingContextFactory
JavaStreamingContextFactory的create方法可以创建JavaStreamingContext,而我们在具体实现的时候覆写了该方法,内部就是调用createContext方法来具体实现。
/** * Factory interface for creating a new JavaStreamingContext */ trait JavaStreamingContextFactory { def create(): JavaStreamingContext }5.2 checkpoint方法
一方面:保持容错 一方面保持状态 在开始和结束的时候每个batch都会进行checkpoint
/** * Sets the context to periodically checkpoint the DStream operations for master * fault-tolerance. The graph will be checkpointed every batch interval. * @param directory HDFS-compatible directory where the checkpoint data will be reliably stored */ def checkpoint(directory: String) { ssc.checkpoint(directory) }5.3 remember方法
流式处理中过一段时间数据就会被清理掉,但是可以通过remember可以延长数据在程序中的生命周期,另外延长RDD更长的时间。
应用场景: 假设数据流进来,进行ML或者Graphx的时候有时需要很长时间,但是bacth定时定条件的清除RDD,所以就可以通过remember使得数据可以延长更长时间。
/** * Sets each DStreams in this context to remember RDDs it generated in the last given duration. * DStreams remember RDDs only for a limited duration of duration and releases them for garbage * collection. This method allows the developer to specify how long to remember the RDDs ( * if the developer wishes to query old data outside the DStream computation). * @param duration Minimum duration that each DStream should remember its RDDs */ def remember(duration: Duration) { ssc.remember(duration) }5.4 getOrCreate方法
如果设置了checkpoint ,重启程序的时候,getOrCreate()会重新从checkpoint目录中初始化出StreamingContext。/** * Either recreate a StreamingContext from checkpoint data or create a new StreamingContext. * If checkpoint data exists in the provided `checkpointPath`, then StreamingContext will be * recreated from the checkpoint data. If the data does not exist, then the provided factory * will be used to create a JavaStreamingContext. * * @param checkpointPath Checkpoint directory used in an earlier JavaStreamingContext program * @param factory JavaStreamingContextFactory object to create a new JavaStreamingContext * @deprecated As of 1.4.0, replaced by `getOrCreate` without JavaStreamingContextFactor. */ @deprecated("use getOrCreate without JavaStreamingContextFactor", "1.4.0") def getOrCreate( checkpointPath: String, factory: JavaStreamingContextFactory ): JavaStreamingContext = { val ssc = StreamingContext.getOrCreate(checkpointPath, () => { factory.create.ssc }) new JavaStreamingContext(ssc) }六、问题总结反思
错误1: 在checkpoint 过的基础上 启动程序,因为我们没有配置完整,会从checkpoint目录读取应用信息,无法初始化ShuffleDStream导致出错。 集群部署的情况下,第一次执行不会出错。
出错原因:- Streaming会定期的进行checkpoint。
- 重新启动程序的时候,他会从曾经checkpoint的目录中,如果没有做额外配置的时候,所有的信息都会放在checkpoint的目录中(包括曾经应用程序信息),因此下次再次启动的时候就会报错,无法初始化ShuffleDStream。
附录:
Scala版本代码:
-
Linux基础命令学习(1)
基础操作
修改机器名 :vim /etc/hostname在文件中修改机器名称为我们想要的名称:hulb 然后 关机: shutdown –h now 重启: reboot –h now
查看ip:ifconfig 通过vim /etc/hosts来建立域名和ip之间的映射关系,访问的时候访问域名hulb就行了
例如:
192.168.1.110 work1
- 查看当前所在目录 :pwd(print work directory)
- 通过cd(change directory)来切换到某个目录
- 通过ls(list)来查看当前目录的文件(夹)的具体名称
- 通过ls –l 来查看当前文件(夹)信息的详情,当然也可以用ll
文件操作
使用vim打开编辑文件是linux程序员最常用的文件编辑器 如果vim打开一个不存在的文件并在文件中插入了内容,则新建一个新文件,新文件中包含了插入的内容
保存退出的命令 首先按下esc建后输入:q! 退出 不保存
保存退出的命令 首先按下esc建后输入::wq 保存并退出
查看linx上文件的内容一般都是使用vim编辑器,或者使用gedit图形化编辑 来查看 也可以用cat 来显示小文件内的内容(直接查看)例如
cat /etc/hosts
more readme.txt 按 enter来翻页
head readme.txt 来看开头
tail readme.txt 查看文件末尾处内容例如查看log 日志内容
tail –f readme.txt
创建文件比较简洁的方式是使用touch命令 例如touch spark.txt
创建目录 mkdir 一般情况下
创建多级目录 mkdir –p spark1/spark2
删除空文件夹 rmdir
man rmdir查看rmdir的用法
使用rm –rf hadoop/强制当前文件夹(包括里面所有内容
拷贝文件 cp hello.txt ./Hellolinux/ 复制到./(当前文件夹) 下 创建一个Hellolinux 拷贝文件到其他机器:scp 移动 mv
mv hello.txt ./hello/ 怎么拷贝到上级目录
如果mv的时候 指定不一样的名称的时候 重命名
mk hello.txt spark.txt 兼具 拷贝和重命名 功能
解压: tar –czvf good.gz test.txt 或者 test/压缩文件夹 要解压的文件名称 加压: tar –zxvf good.gz 解压
权限操作
ll后权限查看:
drwxr-xr-x
第一列:d:文件夹 l:快捷方式
第2-4列:代表当前用户对于该文件夹的具体权限
A) 可读 r 2^2 = 4
B) 可写 w 2^1=2
C) 可执行权限 x 2^0=1
如果从数字的角度 来讲 对文件 最高的权限为7
0 1 2 3 4 5 6 7
第5-7列 :代表当前用户所在的用户组对此的具体权限
第8-10列 :代表用户组外的用户对此的权限
第11列:代表当前文件的链接数 2
第12列 :代表当前用户 root
第13列 :代表当前用户所在的用户组 root
第14列 :代表文件大小 : 2096
15列:代表时间
修改用户和用户组
创建用户: useradd spark
使用chown 来设置文件的拥有者
使用chgrp来改变当前文件所属的用户组
也可以使用chown所属用户:所属用户组 文件名字
-
Spark入门之WordCount
package com.core import org.apache.spark.{SparkConf, SparkContext} /** * Created by lxh on 2016/3/14. * 查看源码快捷键:CTRL + N * */ object WordCount { def main(args: Array[String]) { val conf = new SparkConf() //创建spark conf 对象 conf.setAppName("WordCount app") conf.setMaster("local") val sc = new SparkContext(conf) sc.setLogLevel("WARN") val filepath = "D://testdata//helloSpark.txt" /** * 读取filepath的文件。分片数为1. */ val lines = sc.textFile(filepath, 1) /** * 将行根据空格切割成词。 */ val words = lines.flatMap { lines => lines.split(" ") } /** * 将词转化为元组。出现一次计数为1. */ val pairs = words.map { word => (word, 1) } /** * 将出现次数 累加。 * 并且 转换(词,次数) 为(次数,词) 根据key——次数 进行排序。 然后重新转换成(词,次数) */ val wordCountsOdered = pairs.reduceByKey(_ + _).map(pair => (pair._2, pair._1)).sortByKey(false).map(pair => (pair._2, pair._1)) /** * 对每个元素进行打印输出。 */ wordCountsOdered.foreach(wordNumberPair => println(wordNumberPair._1 + "" + wordNumberPair._2)) /* val wordCount = pairs.reduceByKey(_+_) wordCount.foreach(wordNumberPair => println(wordNumberPair._1+""+wordNumberPair._2 ))*/ while (true){ //循环,以便在web 控制台观察。 } sc.stop() } }
-
Spark程序运行报错(1)
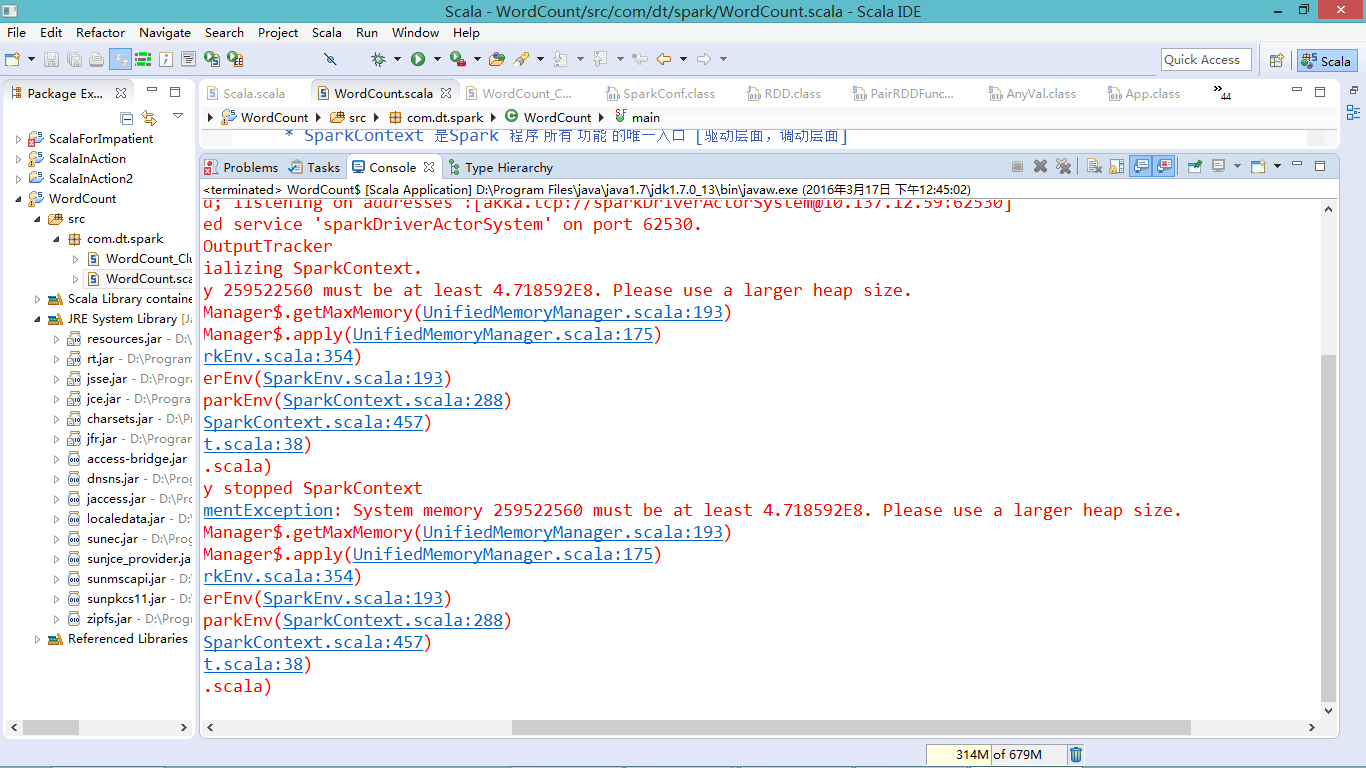
报错内容:
System memory 259522560 must be at least 4.718592E8. Please use a larger heap size.解决:
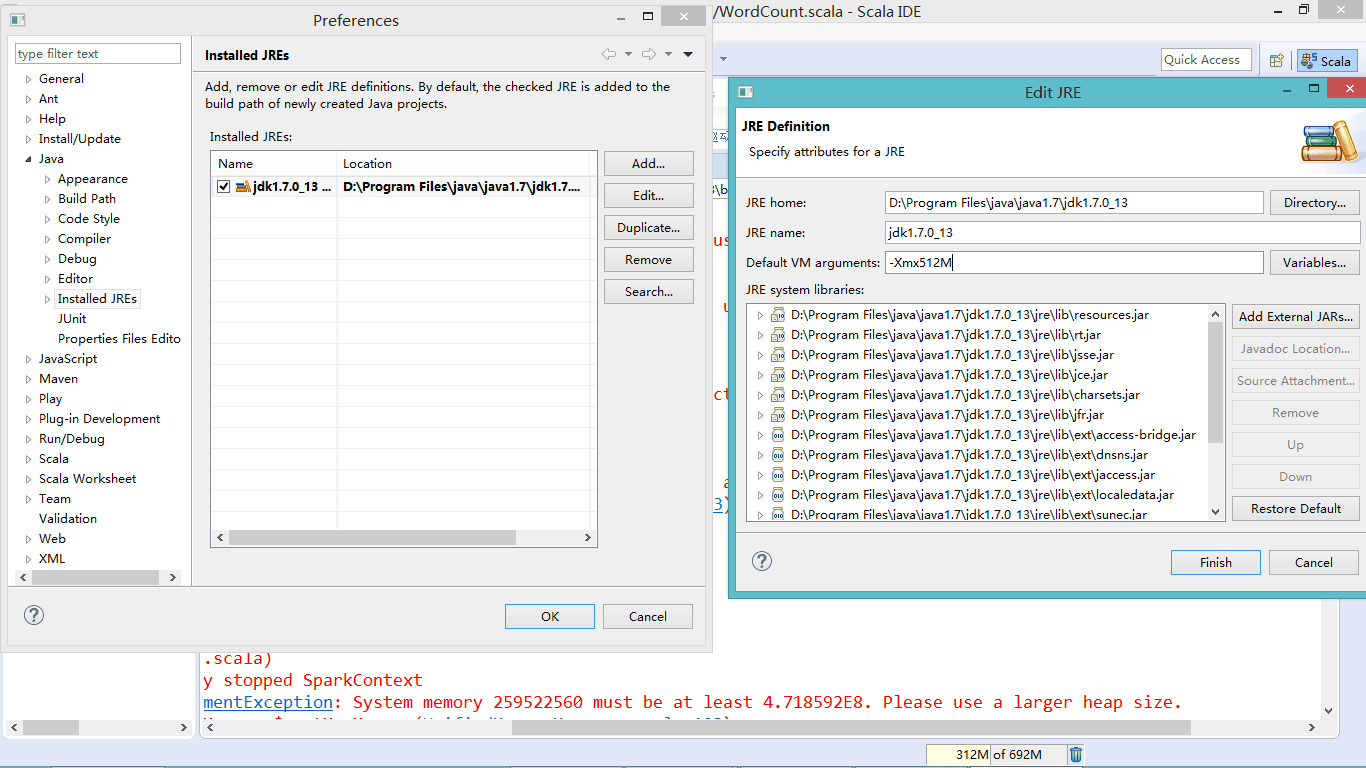
Window——Preference——Java——Installed JREs——选中一个Jre 后 Edit在Default VM arguments 里加入:-Xmx512Meclipse操作图示: